機微データを扱っている企業必見!参照制約を維持しながらデータマスキング!

目次
1.データマスキングとは?
データマスキングとは、IIJクラウドデータプラットフォームサービスの内「クラウドデータハブ」の機能の1つで、データソース間でのデータ連携の際に、事前に設定したルールにもとづいて値を匿名化することで、機微情報などを安全に扱える機能です。
例えば次のケースにおいて、データマスキングは有用な機能となっています。
- 本番環境のデータをテスト環境で利用したいが、個人情報はテスト環境に格納したくない
- 本番環境のデータの論理的特性を維持しつつ、テスト環境でテストデータを生成したい
- オンプレミスとクラウドとのデータ連携を行いたいが、一部の機微情報はオンプレミス上にのみ存在させたい
また、「値をすべて♯に置換する」や「ランダムな値に置換する」などの一般的なマスキングルール以外にも様々なルールを設定できることから、システムの特性やセキュリティポリシーに応じた匿名化が可能です。
※ シンプルなマスキング例はこちらの動画でも紹介しています。ぜひご覧ください。
【デモ動画#2】機微データを匿名化、安全にデータをクラウドへ連携(データマスキング機能)
本記事では「データの論理的特性の維持」にフォーカスを当て、DBで参照制約を定義しているカラムの値をランダム化してSaaSへデータをコピーした場合でも、SaaS上で参照制約が維持されてデータを正しく紐付けできる方法をご紹介します。
2.オンプレDBからSaaSへのデータコピー
次のシチュエーションにおける課題を、データマスキング機能で解決してみましょう。
A社は全国にフィットネスクラブを展開する企業であり、店舗内ではトレーニングのサービスに加え、サプリメントなどの販売も行っている。
A社では会員同意のもと、会員ごとの入退会時期やジム利用頻度、商品購入傾向などをオンプレミスのDB及びBIツールを用いてデータ分析を行い、分析結果は本社の関連部署のみ閲覧可能としている。
この度、店舗からの「サプリメントの販売促進や退会防止のため、店舗でもデータ分析結果を閲覧したい」との要望を受けてその検討を行った。
検討の結果、店舗からのDBやBIツールへのアクセスはセキュリティリスクが高いことから見送り、代替案としてDBから個人情報などの機微データはマスキングした上でSaaSにデータをコピーし、簡易的な分析結果を閲覧できる環境をSaaS上に用意する方針とした。
-
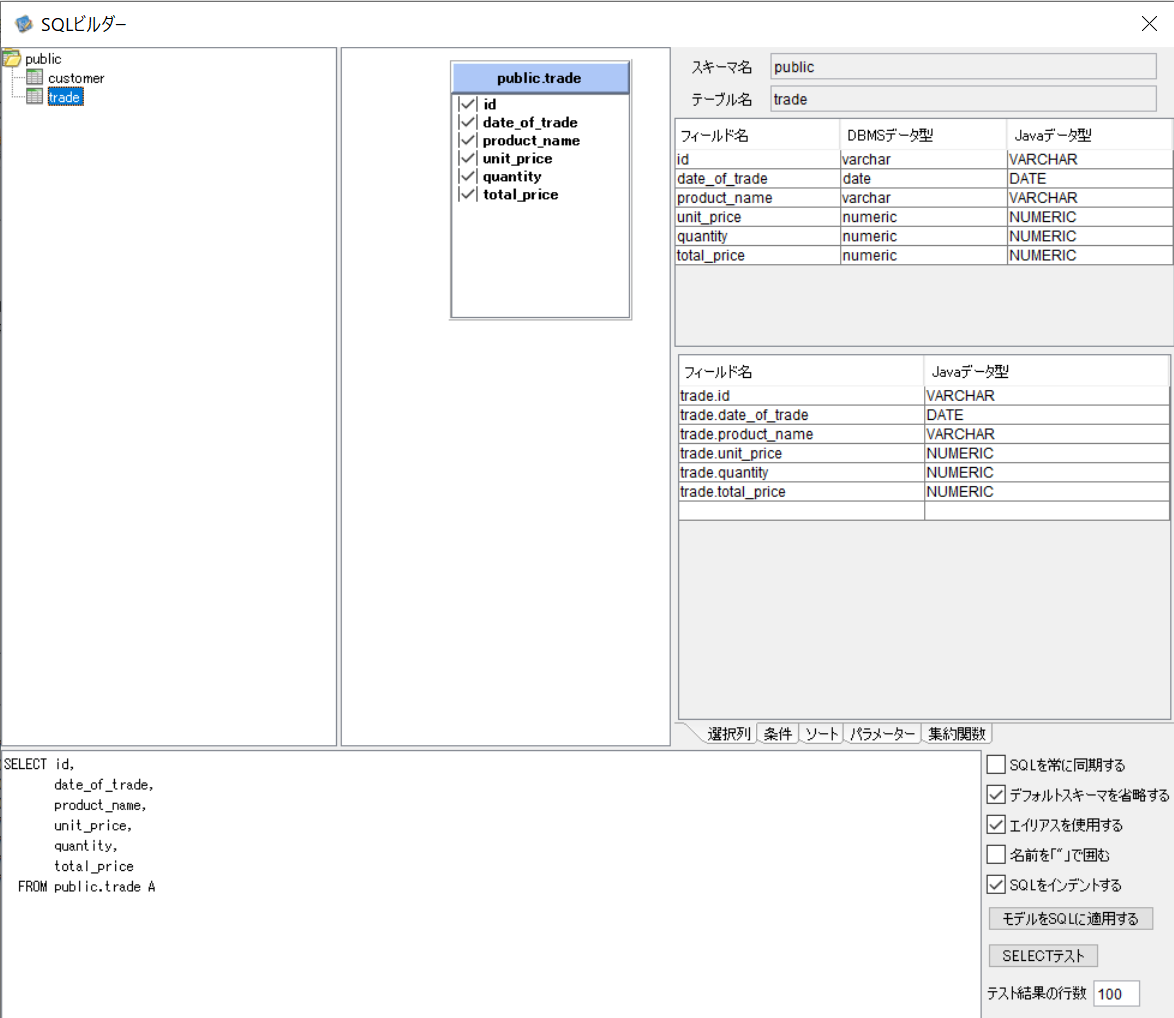
DBのテーブル構成は、会員マスタテーブル「customer」と取引情報テーブル「trade」があり、「customer」と「trade」の間にはそれぞれのid列で参照制約の関係があるものとします。
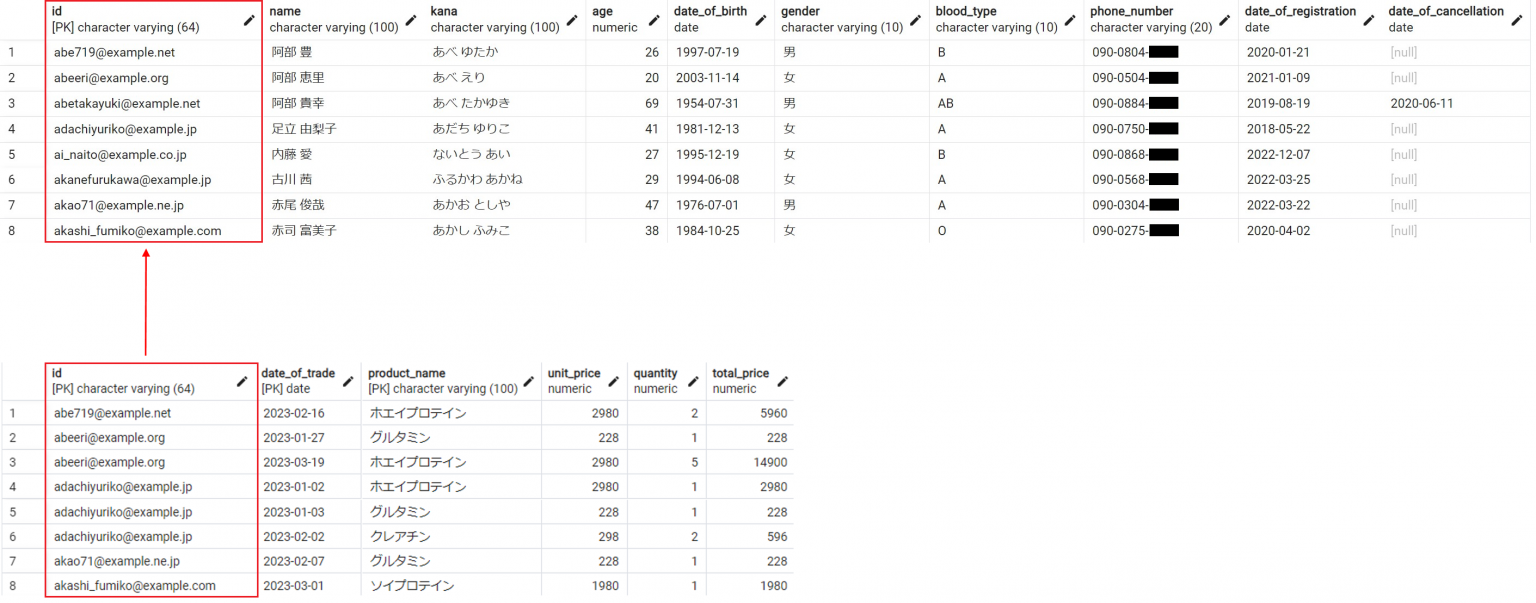
(クリックして拡大)
-
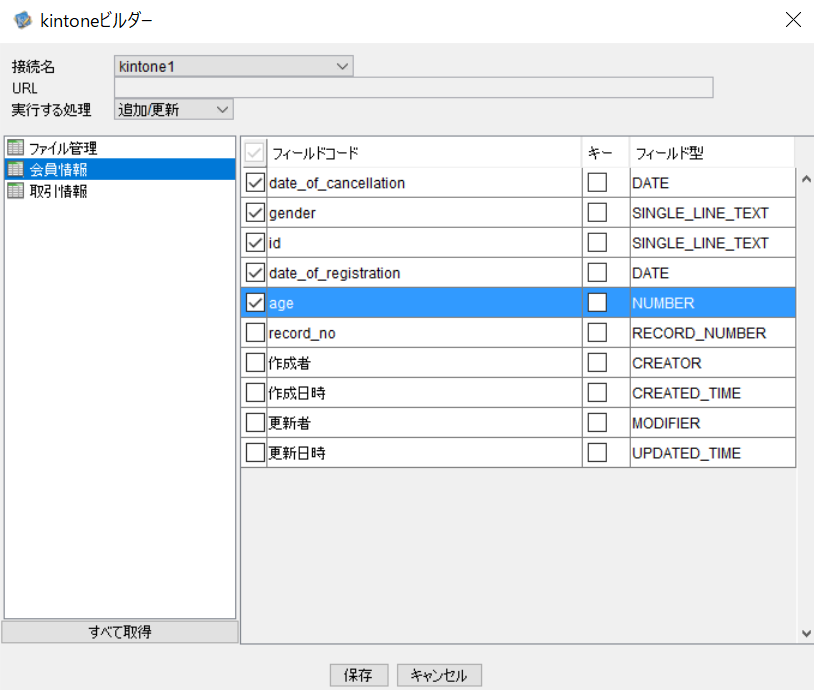
SaaSはサイボウズ社のkintoneを導入。「会員情報」と「取引情報」のアプリがあり、「会員情報」と「取引情報」の間にはそれぞれのid列でルックアップを定義しているものとします。
※ ルックアップを定義することで、「取引情報のID」は「会員情報のID」に存在する値であることが必須です。
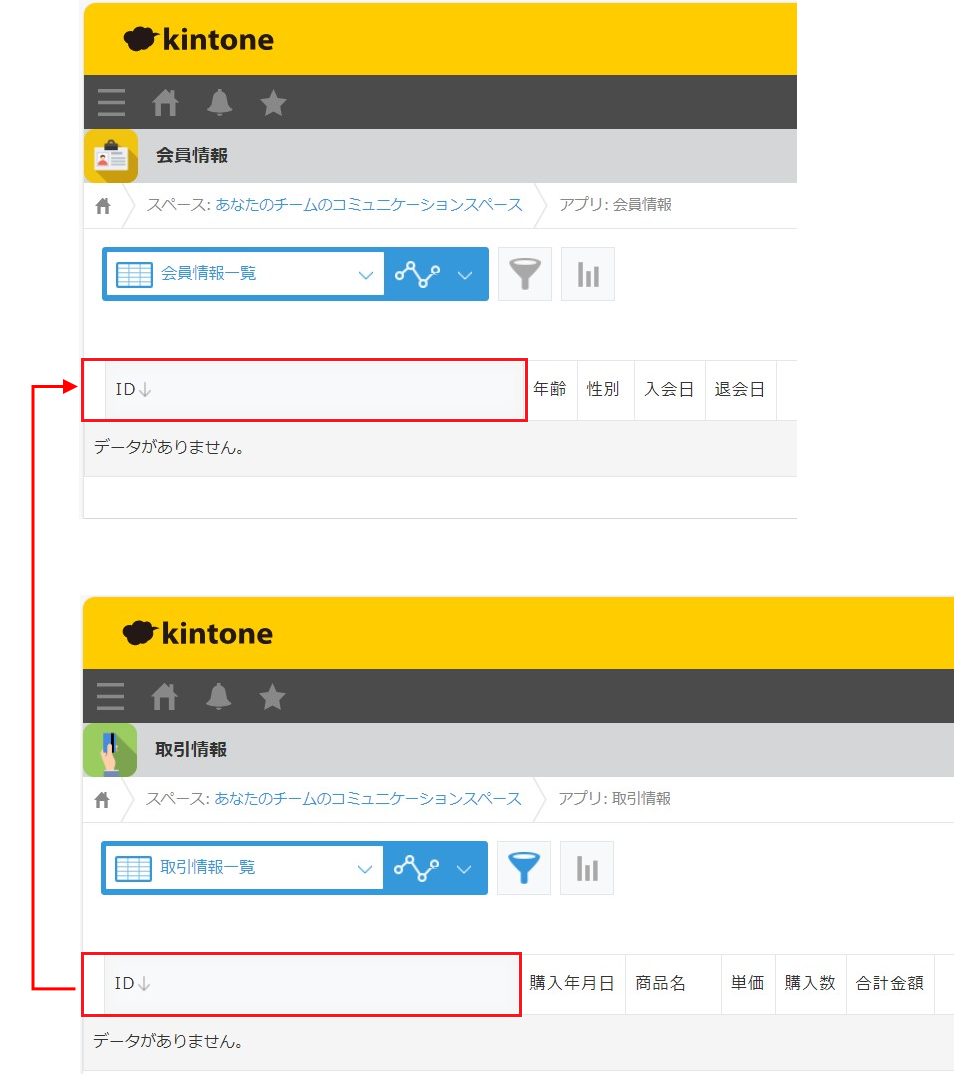
Point
データ分析を行うには?
「会員情報」には商品の購入情報がなく、「取引情報」には年齢や性別といった情報がありません。
このため、「40代の男性はどんな商品を購入しているのか」などのデータ分析を行うには、2つのアプリを「ID」で紐付ける必要があります。「ID」は機微情報なのでランダム化が必須であり、それでいて元々のリレーションの維持が必要です。
| customerテーブル | 加工条件 | 会員情報アプリ |
|---|---|---|
| id ※ trade.idの外部キー |
テーブル(customer、trade) 間の参照制約を維持しランダムな値に置換する | id ※ 取引情報.idの参照先 |
| age | – | 年齢 |
| gender | – | 性別 |
| date_of_registration | – | 入会日 |
| date_of_cancellation | – | 退会日 |
| tradeテーブル | 加工条件 | 取引情報アプリ |
|---|---|---|
| id | テーブル(customer、trade) 間の参照制約を維持しランダムな値に置換する | id |
| date_of_trade | – | 購入年月日 |
| product_name | – | 商品名 |
| unit_price | – | 単価 |
| quantity | – | 購入数 |
| total_price | – | 合計金額 |
3.フロー作成
それでは、先ほどまでの内容を踏まえてフローを作成してみましょう。
フローの概要は次のとおりです。
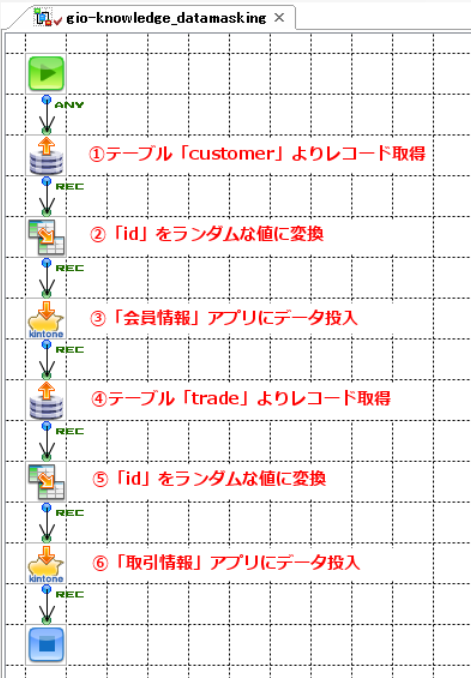
-
RDBGetコンポーネント
DBの会員マスタテーブル「customer」からデータ分析に必要なカラム「id」「年齢(age)」「性別(gender)」「入会日(date_of_registration)」「退会日(date_of_date_of_cancellation)」を指定して全レコードを取得します。
-
Mapperコンポーネント
「id」は機微情報なので、「DataMask」コンポーネントを用いてランダムな値に置換し、次のコンポーネントに出力します。その他のカラムは加工せず出力します。

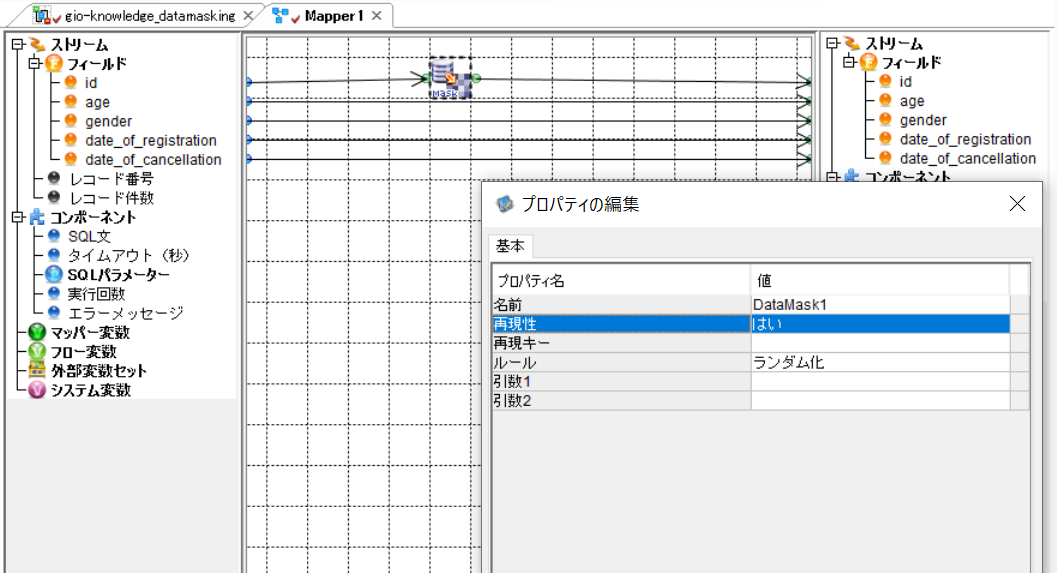
Point
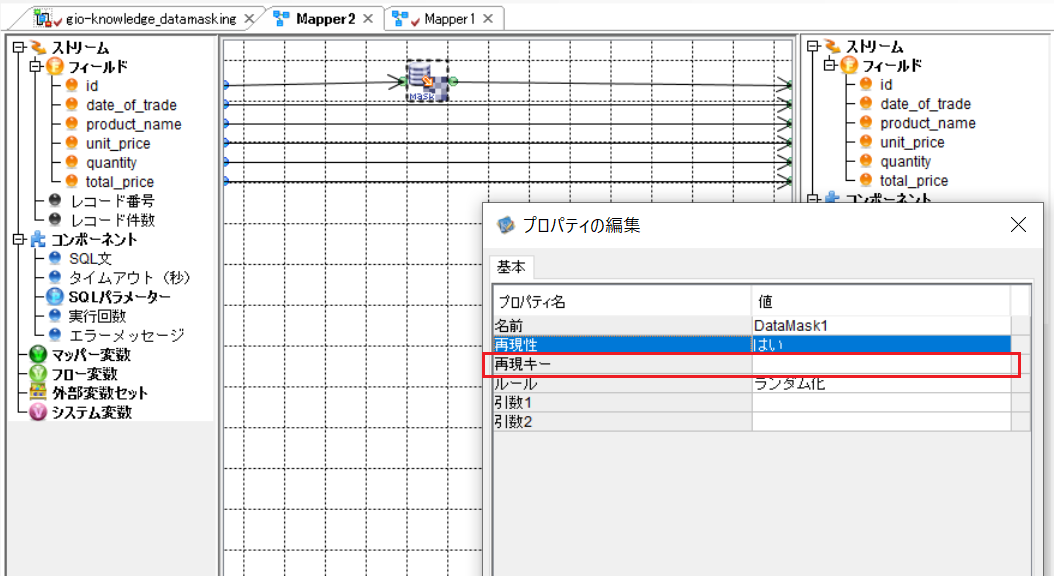
「再現性」「再現キー」
今回のケースでは、「Mapper」コンポーネント内に配置した「DataMask」コンポーネントは、プロパティで「再現性:はい」を選択する必要があります。
「再現性:はい」を選択すると、入力値に対し指定したキー値を用いてランダム化されるため、入力値とキー値が同じであれば、フローを何度も実行した場合や異なるフローでも常に同じ出力結果が得られます。
このように設定することで、テーブル「customer」と「trade」で同一の「id」はそれぞれランダム化されながらも同じ値が出力され、Kintone上でも整合性を保ってデータを紐づけられます。
※ 画像のように「再現キー」を空白とした場合はキー値に「0」が設定されたものとして処理されます。 -
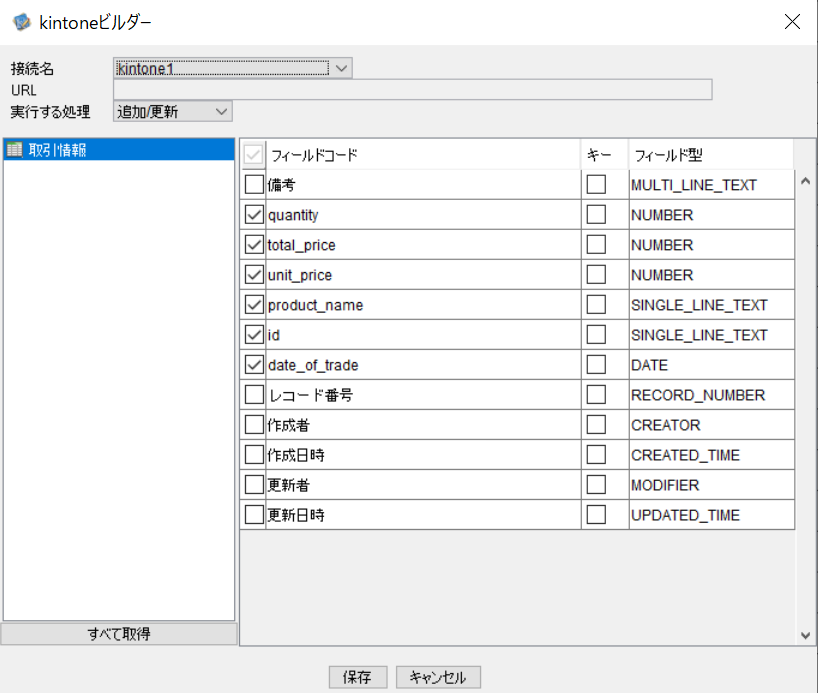
kintonePutコンポーネント
「Mapper1」コンポーネントで加工したデータをKintoneの「会員情報」アプリに出力します。
-
RDBGetコンポーネント
1と同様に「trade」テーブルから全レコードを取得します。
-
Mapperコンポーネント
2と同様に「id」を「再現性:はい」でランダム化し次のコンポーネントに出力します。
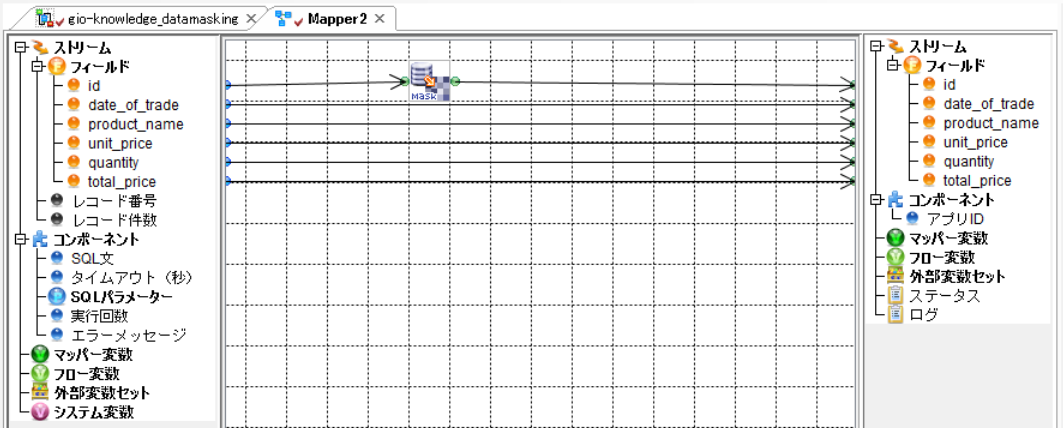
2つのKintoneアプリをIDで紐付けることが目的なので、「DataMask」コンポーネントの「再現キー」の値は「Mapper1」の「DataMask」コンポーネントと同じ値にする必要があります。
-
kintonePutコンポーネント
3と同様に「Mapper2」で加工したデータをKintoneの「取引情報」アプリに対して出力します。
以上でフローは完成です。
それでは実行してみましょう。
無事に正常終了しました。
4.実行結果
データ分析の前に、2つのKintoneアプリそれぞれの「ID」が同じ値でランダム化されていることを確認してみましょう。
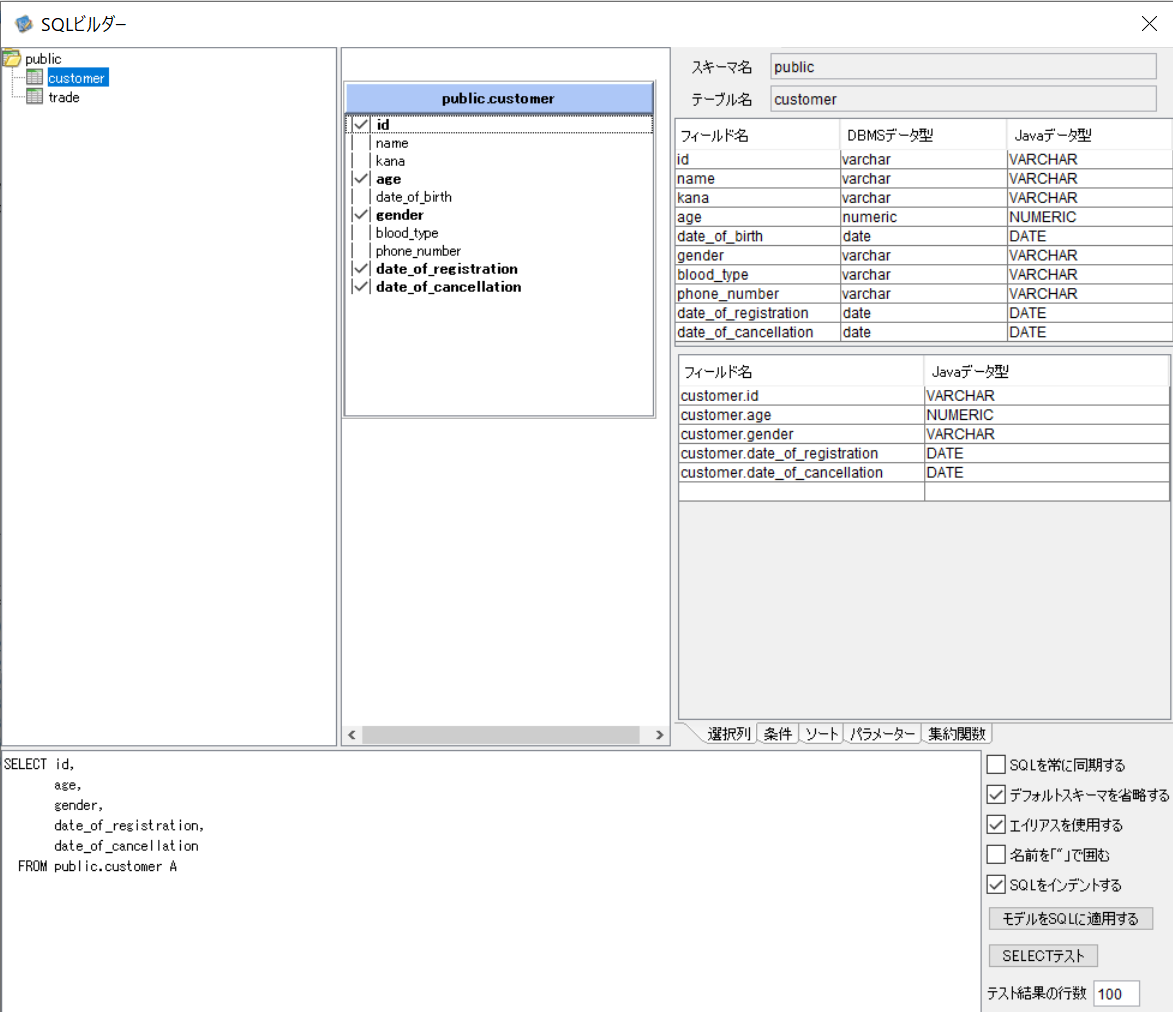
DBで「customer」と「trade」を結合し、どの会員がいつ何を購入したのかを抽出します。
SELECT A.id,A.age,A.gender,A.date_of_registration,A.date_of_cancellation,
B.date_of_trade,B.product_name,B.unit_price,B.quantity
FROM public.customer as A
inner join public.trade as B
on A.id = B.id
ORDER BY A.id
会員「adachiyuriko@example.jp 41歳 女性」を見ると、2023年の1月2日、1月3日、及び2月2日に商品の購入履歴があることが分かります。
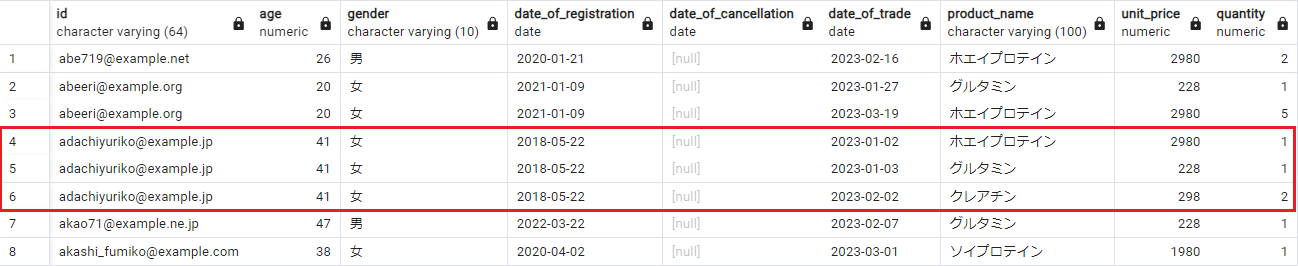
(クリックして拡大)
このことを踏まえてKintoneの「会員情報」アプリを確認すると、年齢や性別などのID以外の情報から、ID「adachiyuriko@example.jp」はランダムな文字列「jlsriZbCdPVd.oqtCUKM!KL」に置換されていることが分かります。
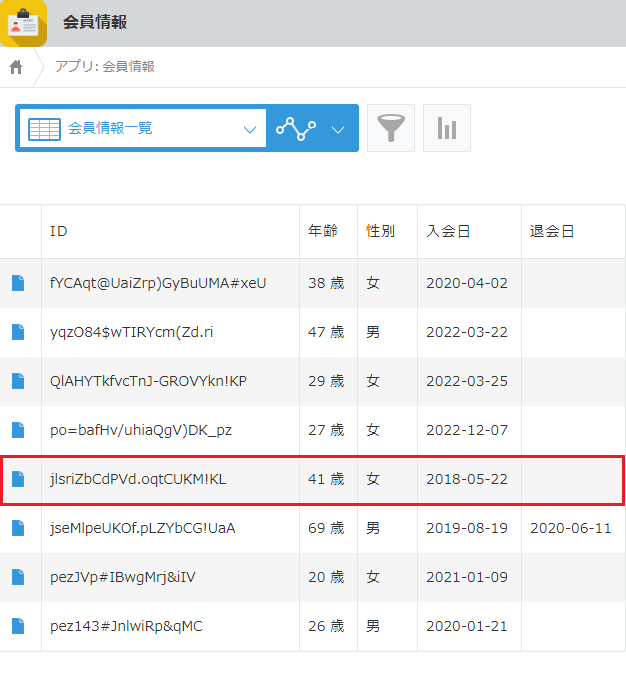
続けて「取引情報」アプリを確認すると、ID「jlsriZbCdPVd.oqtCUKM!KL」は、DB上のID「adachiyuriko@example.jp」と同一の商品購入履歴があることが分かります。
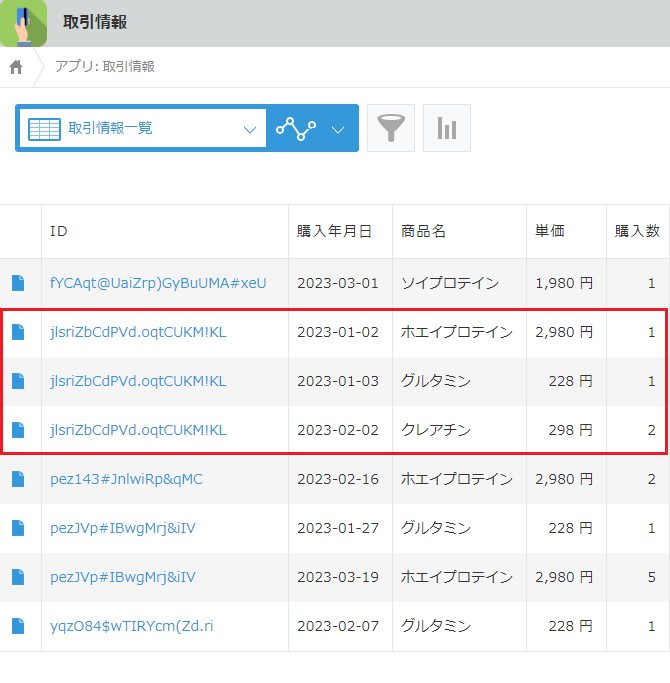
DBのテーブル「customer」「trade」から、Kintoneアプリ「会員情報」「取引情報」それぞれに対し、機微情報をマスクしながらも参照制約を維持してデータをコピーできました。
それでは、目的であったデータ分析を行ってみます。40代~50代男性はどんな商品を購入しているのでしょうか。
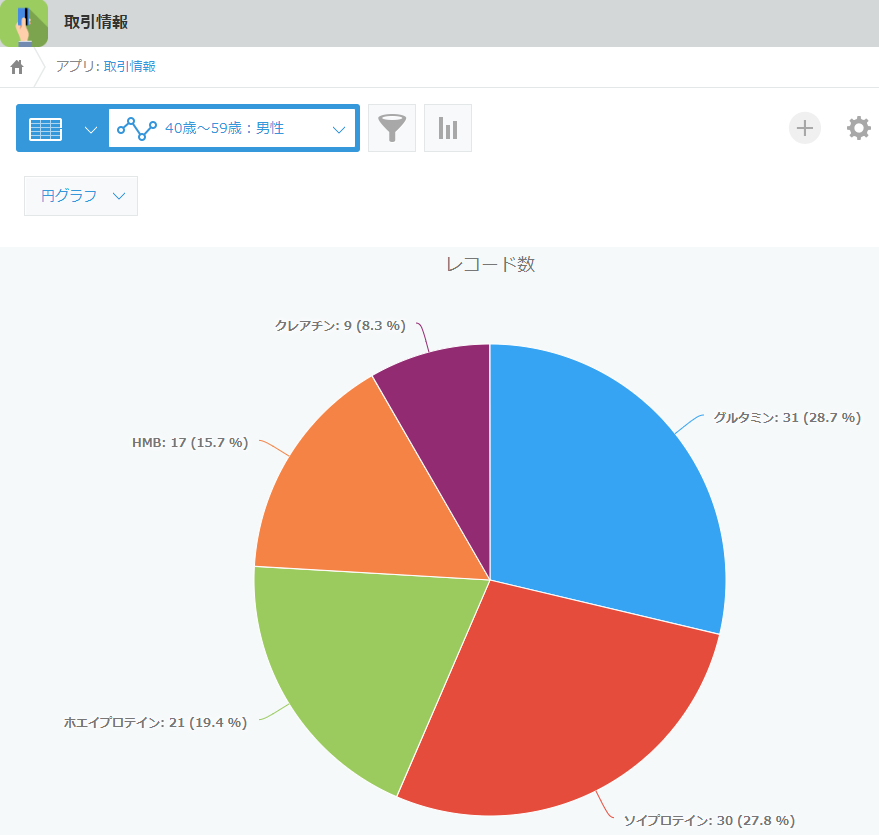
(クリックして拡大)
いかがでしょうか。「データマスキング」は今回のケース以外にも様々なシーンにおいて役立つ機能になっています。ぜひご活用ください。
【Appendix】NGケース「再現性:いいえ」
おまけで、NGケースとして「DataMask」コンポーネントのプロパティで「再現性:いいえ」を選択した場合の結果を見てみましょう。
3-5の「Mapper」コンポーネント内「DataMask」コンポーネントで「再現性:いいえ」あるいは「再現性:はい」で異なる再現キーを設定して実行すると、次のようなエラーになってしまいます。
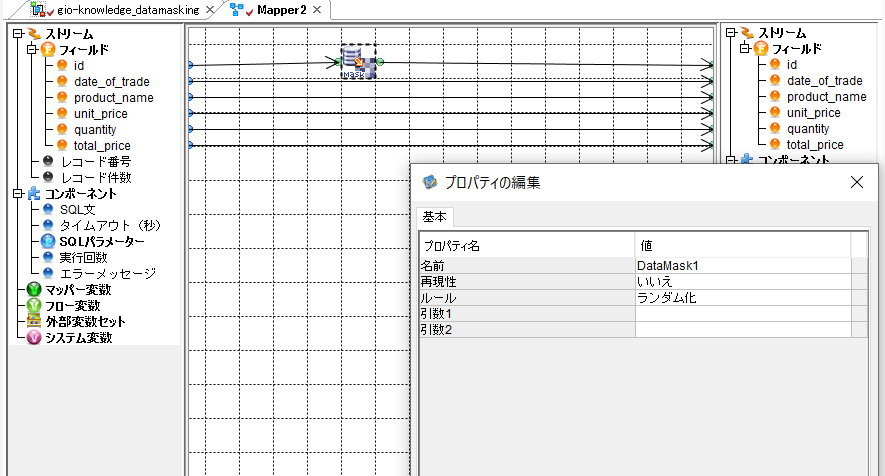
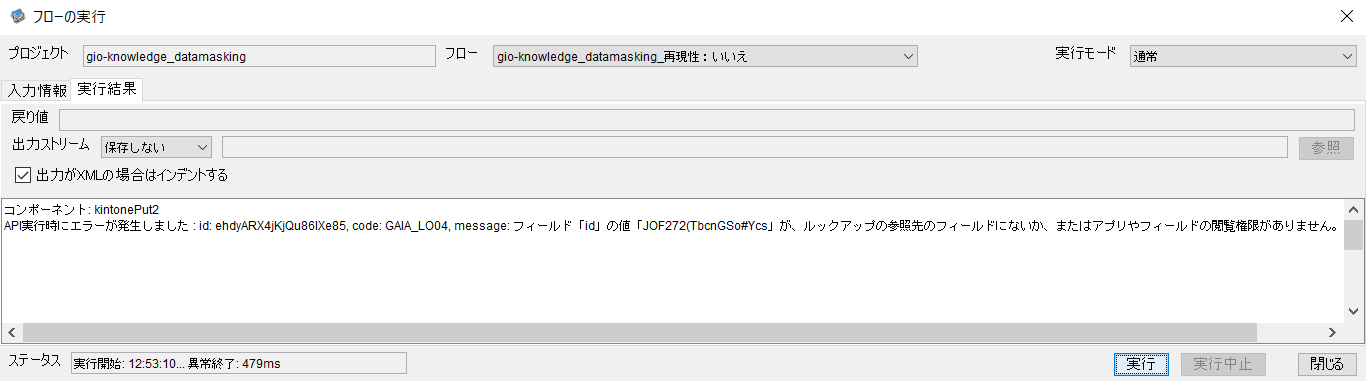
(クリックして拡大)
このID「JOF272(TbcnGSo#Ycs」は次のように「会員情報」アプリに存在しない値であることがエラーの原因です。
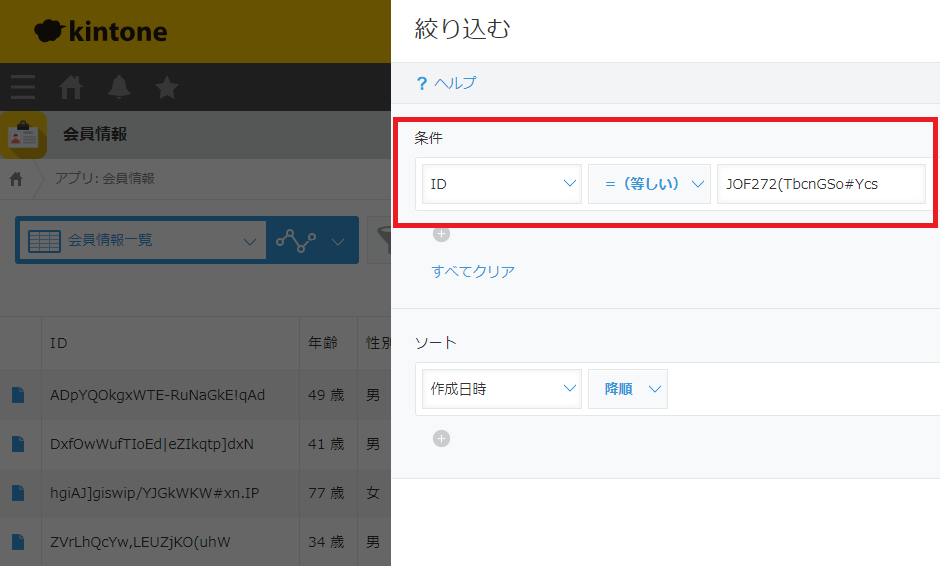
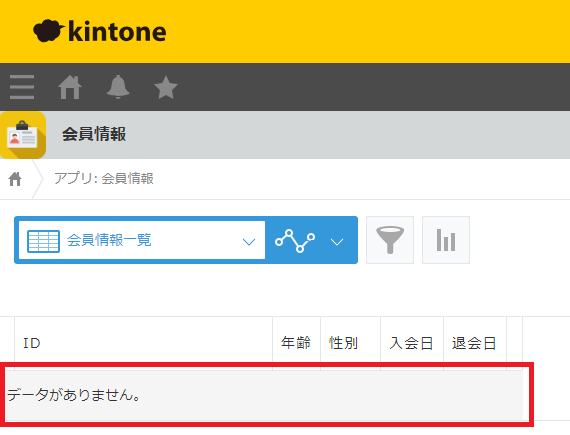
このように、2つの「Datamask」コンポーヘントへの入力値が同一でも、「再現性:はい」かつ再現キーを同一にしない場合は、異なる出力結果になることが分かります。
※ データ量や値によってはエラーとはならずに、「取引情報」のIDが「会員情報」の別のIDと一致してしまう場合もあります。
IIJ プロフェッショナルサービス第一本部 ITサービスインテグレーション4部 1課



サービスについてのお問い合わせは


